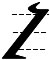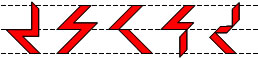
The Ithkuil script is a morpho-phonemic script, i.e., the individual characters do not simply convey phonetic (i.e., phonological) information, but also convey grammatical (i.e., morphological) information. Many of the characters are purely morphological in function and without any set phonological value, their specific phonological interpretation being up to the reader based on the flexiblility and options inherent in Ithkuil morpho-phonology.
| 11.1 CHARACTER TYPES |
There are four types of characters used in the Ithkuil Script: Primary Case/Aspect characters, Secondary Case/Aspect characters, Tertiary characters, and Consonantal characters. Additionally, there are symbols used for numbers (to be discussed in Chapter 12), separate rules for transliterating non-Ithkuil words alphabetically, and a few punctuation symbols.
11.1.1 Primary Case/Aspect Markers
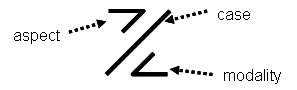
If present, the Case-Marker character is the first written character in a word. It is normally used to convey the case or case-frame of a formative, however, when the case or case-frame of the formative is the OBLIQUE, it can instead be used to convey one of the following: Aspect, Modality, Validation, or Valence. In addition to these categories, the character also shows the following categories: Configuration, Essence, Affiliation, Extension, Mood, and Version.
Primary Case/Aspect characters are recognizable by the absence of a top or bottom horizontal bar (as is found on all consonantal characters below), as well as a diagonal section of the character either below or above the horizontal mid-line. This diagonal section of the character will always change direction at the horizontal midline of the character. Examples:
11.1.2 Secondary Case/Aspect Markers
As stated above, Primary Case markers can be used to convey only one of the following categories at a time: Case, Aspect, Modality, Validation, or Valence. However, it is often necessary to be able to show more than one of these categories on a formative (i.e., the formative has non-default values for more than one of these categories). In such cases, secondary Case/Aspect Markers can be used. These characters are capable of showing Case, Aspect, and Modality simultaneously. Additionally, they can be used to show non-default values for the categories of Phase, Sanction, Designation, and Perspective.
Secondary Case/Aspect markers can be recognized by the presence of a diagonal bar extending the entire length of the character from the top-line (or even above the top-line) all the way to the bottom-line (or even below the bottom-line). This diagonal bar may be broken or modified in the middle by either a horizontal or vertical zig-zag, but will always continue in the same direction as before coming out of the break or zig-zag (unlike Primary Case/Aspect characters which have a change in direction beginning at the horizontal mid-line). Examples:

11.1.3 Tertiary Characters
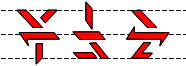
These characters are used, when necessary, to convey the combination of two different aspects, aspect plus modality, aspect plus valence, aspect plus validation, validation plus modality, valence plus modality, or valence plus validation. They are recognizable by having a horizontal bar at the mid-line of the character which is not connected to any vertical or diagonal bars above or below the horizontal bar. The ends of the horizontal bar may be modified by points facing upward or downward. Examples:
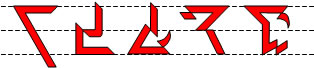
11.1.4 Consonantal Characters
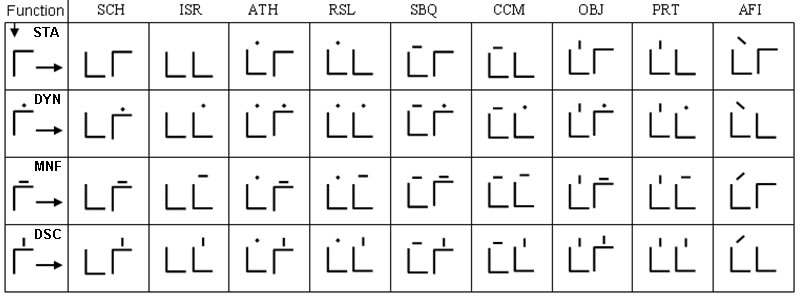
These characters are used to convey the consonantal root Cr, the incorporated root Cx (if present), and any Vx-C consonantal suffixes the formative may have. They are placed following any characters of Types 1, 2, or 3, in the order (Cx)-Cr-(VxC)-(VxC... etc.) If an incorporated root Cx is present, it is indicated by vertically inverting the Consonantal character in order to distinguish it from the following Cr character. The Cr character is also used to convey the categories of Function, Format, Context, Illocution, and Relation, while the VxC character conveys affix type and degree, as well as Bias.
Consonantal characters are recognizable by the presence of a horizontal bar either along the top-line or the bottom-line, the ends of which may be modified. Examples:
11.1.5 Example of the Script in Operation
To illustrate further how a morpho-phonemic script operates, we can analyze the function of each character in the following Ithkuil sentence:
Igrawileiţrar oi eglulôn.
DYN-‘eat food’-FAC-HOR-NRM/DEL/M/CSL/UNI-NA11/5-EXT2/6-IFL PCL STA-‘illness’-IND-NRM/DEL/M/CSL/UNI-AGC2/7-IFL
If only the physician wouldn’t eat his food in one gulp like that.
The shape of this character indicates it is a primary character showing GENITIVE case or, alternately, PRECLUSIVE aspect. The bar below it indicates default PROCESSUAL version and also serves to indicate the character carries its alternate value, i.e., PRECLUSIVE aspect. The lack of a superposed diacritic over the character indicates FACTUAL mood as well as the fact that the word is a formative and not a personal reference adjunct. The lack of a diacritic alongside the character indicates MONADIC perspective and INFORMAL designation. The lack of modifications to the top half of the character indicates NORMAL essence and UNIPLEX configuration. The lack of modifications to the bottom half of the character indicates DELIMITIVE extension and CONSOLIDATIVE affiliation.
The shape of this character indicates it is a consonantal character, /g/; the bottom-half modification adds an /r/ giving the form /gr/. Its position following a primary case/aspect character shows it is a Cr root, -GR-. The lack of modication to the top-bar indicates Pattern 1, Stem 1, ‘food and drink; eat and drink one’s food’ as well as indicating UNFRAMED relation. The superposed dot diacritic indicates DYNAMIC function and default EXISTENTIAL context. The fact the character is not vertically inverted shows the word carries no incorporated stem or format. The absence of an underposed diacritic shows the stem is not triconsonantal or tetraconsonantal. The angular diacritic alongside the character indicates both HORTATIVE illocution and negative polarity (i.e., equivalent to carrying the NA11/5 suffix).
The shape of this character indicates it is a consonantal character, /ţ/. Its position following a Cr root and the fact it is vertically inverted indicates it is a V2C derivational suffix. The modification of the bottom-half (actually the top- half due to the vertical inversion of the character) prefixes a consonantal /r/ giving the phonological form /rţ/ which is the EXT suffix. The angular diacritic over the character indicates the suffix is Degree 6. The lack of modifications to the top-half (actually bottom-half due to vertical inversion) indicates the formative carries no Bias.
The shape of this character, its position following a consonantal suffix, the lack of top-half or bottom-half modifications, and the absence of any diacrtics all serve to indicate the start of a new word which is a formative (as opposed to a personal reference adjunct) and that it is a primary character showing INDUCIVE case, PROCESSUAL version, NORMAL essence, UNIPLEX configuration, DELIMITIVE extension, CONSOLIDATIVE affiliation, INFORMAL designation, and MONADIC perspective.
The shape of this character indicates it is a consonantal character, /g/; the bottom-half modification adds an /l/ giving the form /gl/. Its position following a primary case/aspect character shows it is a Cr root, -GL-. The modication to the top-bar indicates Pattern 1, Stem 2, ‘illness/sickness’ as well as indicating UNFRAMED relation. The absence of a superposed diacritic indicates STATIVE function and default EXISTENTIAL context. The fact the character is not vertically inverted shows the word carries no incorporated stem or format. The absence of an underposed diacritic shows the stem is not triconsonantal or tetraconsonantal. The absence of a diacritic alongside indicates default ASSERTIVE illocution.
The shape of this character indicates it is a consonantal character, /n/. Its position following a Cr root, the fact it is vertically inverted, and the absence of any bottom-half (actually top-half due to vertical inversion) indicates it is a V2C derivational suffix, AGC. The grave accent-like diacritic over the character indicates the suffix is Degree 7. The lack of modifications to the top-half (actually bottom-half due to vertical inversion) indicates the formative carries no Bias.
The absence of any secondary case/aspect character or placeholder characters within these formatives indicate default CONTEXTUAL phase and PROPOSITIONAL sanction on both formatives.
As can be seen from the above analysis, the only purely phonological information conveyed by the written form of this sentence consists of the consonantal groupings /gr/ /rţ/ /gl/ and /n/. The remainder conveys solely morphological/grammatical information by which the reader “re-constructs” the pronunciation based on his/her knowledge of Ithkuil morpho-syntax and the various optional ways in which it maps to the language’s morpho-phonology. The non-alphabetic nature of the script, along with the flexibility of Ithkuil morpho-phonology, allows the written form of this sentence to be read in many equivalent ways, such as:
Igrawileiţrar oi eglulôn.
Oi eirţ igrawilar ôn eglul.
Çtar-ryigraleiţrar eglulôn.
If only the physician wouldn’t eat his food in one gulp like that.
| 11.2 DIRECTION OF WRITING |
The Ithkuil script is written in a horizontal boustrophedon (i.e., zig-zag) manner, in which the first and every subsequent odd-numbered line of writing is written left-to-right, while the second and every subsequent even-numbered line of writing is written right-to-left. The characters within even-numbered lines written right-to-left retain their normal lateral orientation and are not laterally reversed (i.e., they are not written in a mirror-image manner). A small left-pointed mark like an arrow or left-pointing triangle is placed at the beginning of even-numbered lines (i.e., those written right-to-left) to remind the reader of the line’s orientation. The following paragraph shows by analogy how the script is written.
THE ITHKUIL SCRIPT IS WRITTEN IN A HORIZONTAL BOUSTROPHEDON
TNEUQESBUS YREVE DNA TSRIF EHT HCIHW NI ,RENNAM (GAZ-GIZ ,.E.I)
ODD-NUMBERED LINE OF WRITING IS WRITTEN LEFT-TO-RIGHT, WHILE
-TIRW FO ENIL DEREBMUN-NEVE TNEUQESBUS YREVE DNA DNOCES EHT
ING IS WRITTEN RIGHT-TO-LEFT.
| 11.3 PRESENTATION & ANALYSIS OF THE CHARACTER TYPES |
The sub-sections below provide the details of the various characters and character-permutations associated with each character type.
11.3.1 Primary Case/Aspect Characters
The neutral default shape for a Primary Case/Aspect character is as follows: ![]()
This shape can then be mutated into a variety of derivative shapes by means of changing the direction of the bars of the character at the mid-line point, extending the mid-line point horizontally, and changing the corner-like vertices to “offset” connections, as illustrated by the examples in Section 11.1.1 above:
The common recognizable elements in any Primary Case/Aspect character, and what distinguishes such characters from the other three character-types, are (1) the absence of a horizontal bar along the top-line and the bottom-line, (2) a diagnonal bar running from the mid-line to either the top-line or to the bottom-line or both, and (3) a change in the diagonal bar’s (or bars’) direction at the mid-line.
A Primary Case/Aspect character usually conveys the case of the formative (see Chapter 4), however, in the absence of case (e.g., as with a verb), or when the case is OBLIQUE, the character can convey one of the following other categories: Aspect, Modality, Valence, or Validation.
The various ways the character conveys these categories is described below.
(NOTE: If a formative is the first word in a sentence and carries no Aspect or Modality, and the other five categories are in their neutral/default modes (i.e., MNO valence, CNF validation, PRC version, CTX phase, and PPS sanction), then the Primary Aspect/Modality character will be missing, i.e., is not written.)
11.3.1.1 Case: The 96 cases are shown by the main body of the character – there are 24 basic forms corresponding to the first 24 cases. The next group of 24 cases utilizes the same 24 forms laterally reversed. The latter 48 cases utilize these same forms, vertically reversed. These forms are shown below (note that the vertical symmetricality of Forms 1 and 25, as well as Forms 3 and 27, require that Forms 49, 51, 73, and 75 have special forms):
Table 35: Primary Case characters (Note that for the purposes of this table, the VOCATIVE case is shown in Position No. 48.)
1 OBL |
|
25 PUR |
|
49 EXC |
|
73 CMP1A |
|
2 IND |
|
26 CSD |
|
50 AVR |
|
74 CMP1B |
|
3 ABS |
|
27 ESS |
|
51 CMP |
|
75 CMP1C |
|
4 ERG |
|
28 ASI |
|
52 SML |
|
76 CMP1D |
|
5 EFF |
|
29 FUN |
|
53 ASS |
|
77 CMP1E |
|
6 AFF |
|
30 TFM |
|
54 CNR |
|
78 CMP1F |
|
7 DAT |
|
31 REF |
|
55 ACS |
|
79 CMP1G |
|
8 INS |
|
32 CLA |
|
56 DFF |
|
80 CMP1H |
|
9 ACT |
|
33 CNV |
|
57 PER |
|
81 CMP2A |
|
10 DER |
|
34 IDP |
|
58 PRO |
|
82 CMP2B |
|
11 SIT |
|
35 BEN |
|
59 PCV |
|
83 CMP2C |
|
12 POS |
|
36 TSP |
|
60 PCR |
|
84 CMP2D |
|
13 PRP |
|
37 CMM |
|
61 ELP |
|
85 CMP2E |
|
14 GEN |
|
38 COM |
|
62 ALP |
|
86 CMP2F |
|
15 ATT |
|
39 CNJ |
|
63 INP |
|
87 CMP2G |
|
16 PDC |
|
40 UTL |
|
64 EPS |
|
88 CMP2H |
|
17 ITP |
|
41 ABE |
|
65 PRL |
|
89 CMP3A |
|
18 OGN |
|
42 CVS |
|
66 LIM |
|
90 CMP3B |
|
19 PAR |
|
43 COR |
|
67 LOC |
|
91 CMP3C |
|
20 CRS |
|
44 DEP |
|
68 ORI |
|
92 CMP3D |
|
21 CPS |
|
45 PVS |
|
69 PSV |
|
93 CMP3E |
|
22 PRD |
|
46 PTL |
|
70 ALL |
|
94 CMP3F |
|
23 MED |
|
47 CON |
|
71 ABL |
|
95 CMP3G |
|
24 APL |
|
48 VOC |
|
72 NAV |
|
96 CMP3H |
|
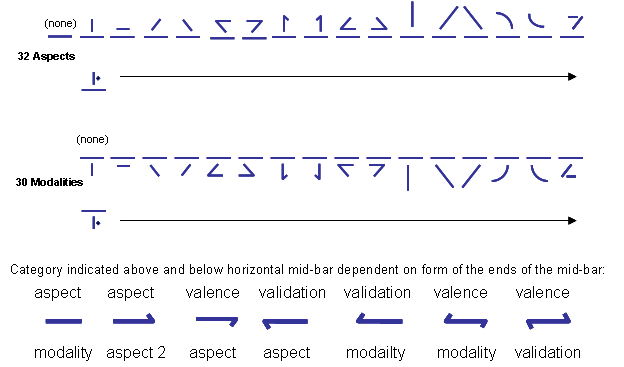
11.3.1.2 Configuration and Essence: These two categories (see Sections 3.1 and 3.5) are shown via modifications to the top “end” of the Primary Case/Aspect character, as shown below:
Table 36: Modifications to Primary Case/Aspect Characters Indicating Configuration & Essence
|
NRM essence |
RPV essence |
1 UNI |
|
|
2 DPX |
|
|
3 DCT |
|
|
4 AGG |
|
|
5 SEG |
|
|
6 CPN |
|
|
7 COH |
|
|
8 CST |
|
|
9 MLT |
|
|
11.3.1.3 Extension and Affiliation: These two categories (see Sections 3.4 and 3.2) are shown via the bottom “end” of the Primary Case/Aspect character, as shown below:
Table 37: Modifications to Primary Case/Aspect Characters Indicating Extension & Affiliation
|
AFFILIATION |
|||
|
CSL |
ASO |
VAR |
COA |
1 DEL |
|
|
|
|
2 PRX |
|
|
|
|
3 ICP |
|
|
|
|
4 TRM |
|
|
|
|
5 DPL |
|
|
|
|
6 GRA |
|
|
|
|
11.3.1.4 Perspective and Designation: These two categories (see Sections 3.3 and 3.7) are shown via a diacritic mark written alongside the mid-line of the Primary Case/Aspect character following the character in the direction the line is being written. These diacritics are shown below:
Table 38: Diacritics on Primary Case/Aspect Characters Indicating Perspective & Designation
|
PERSPECTIVE |
|||
|
MONADIC |
UNBOUNDED |
NOMIC |
ABSTRACT |
INFORMAL |
|
|
|
|
FORMAL |
|
|
|
|
11.3.1.5 Mood: This category (see Section 5.2) is shown via a superposed diacritic above the Primary Case/Aspect character, as follows:
Table 39: Diacritics on Primary Case/Aspect Characters Indicating Mood
1 FAC |
2 SUB |
3 ASM |
4 SPC |
5 COU |
6 HYP |
7 IPL |
8 ASC |
|
|
|
|
|
|
|
|
Note: If instead of one of the above, the Primary Case/Aspect character carries a superposed horizontal bar diacritic, ![]() this indicates that the word is a Personal Reference adjunct rather than a formative. In addition, high-toned personal reference adjuncts carry an underposed dot diacritic on the same Primary Case/Aspect character. (The presence of the superposed horizontal bar diacritic on the character prevents this underposed dot from being confused with Version marking explained in the section immediately below.)
this indicates that the word is a Personal Reference adjunct rather than a formative. In addition, high-toned personal reference adjuncts carry an underposed dot diacritic on the same Primary Case/Aspect character. (The presence of the superposed horizontal bar diacritic on the character prevents this underposed dot from being confused with Version marking explained in the section immediately below.)
11.3.1.6 Version: This category (see Section 5.8) is shown via an underposed diacritic below the Primary Case/Aspect character. These diacritics come in two varieties, standard and alternate. Use of the alternate form of the diacritic indicates that the main body of the character conveys a category other than Case (explained below in Section 11.3.1.7).
Table 40: Diacritics on Primary Case/Aspect Characters Indicating Version
|
1 PRC |
2 CPT |
3 INE |
4 INC |
5 PST |
6 EFC |
standard |
|
|
|
|
|
|
alternate |
|
|
|
|
|
|
11.3.1.7 Aspect, Modality, Valence and Validation: If the underposed version diacritic shown on a Primary Case/Aspect character is in an alternate form (as shown in Table 40 above), then the main body of the character no longer conveys the category of Case, but rather one of the following four categories: Aspect, Modality, Valence, or Validation, depending on which character is displayed (see Sections 5.10, 6.1, 5.7, and 5.9 respectively, for explanations of these categories). The characters normally reserved for Case Nos. 1 through 32 instead indicate the 32 aspects. The characters normally reserved for Case Nos. 33 through 62 instead indicate the 30 modalities. The characters normally reserved for Case Nos. 63 through 76 instead indicate the fourteen valences, and the characters normally reserved for Case Nos. 77 through 90 instead indicate the fourteen validations. These values are shown in the following tables:
Table 41: Primary Aspect Characters
(when accompanied by alternate form of underposed Version diacritic)
1 RTR |
|
9 RSM |
|
17 PMP |
|
25 DSC |
|
2 PRS |
|
10 CSS |
|
18 CLM |
|
26 CCL |
|
3 HAB |
|
11 RCS |
|
19 PTC |
|
27 CUL |
|
4 PRG |
|
12 PAU |
|
20 TMP |
|
28 IMD |
|
5 IMM |
|
13 RGR |
|
21 MTV |
|
29 TRD |
|
6 PCS |
|
14 PCL |
|
22 CSQ |
|
30 TNS |
|
7 REG |
|
15 CNT |
|
23 SQN |
|
31 ITC |
|
8 EXP |
|
16 ICS |
|
24 EPD |
|
32 CSM |
|
Table 42: Primary Modality Characters
(when accompanied by alternate form of underposed Version diacritic)
1 DES |
|
7 OPR |
|
13 IMS |
|
19 NEC |
|
25 CML |
|
2 ASP |
|
8 CPC |
|
14 ADV |
|
20 DEC |
|
26 DVR |
|
3 EXV |
|
9 PRM |
|
15 ITV |
|
21 PTV |
|
27 DVT |
|
4 CRD |
|
10 PTN |
|
16 ANT |
|
22 VOL |
|
28 PFT |
|
5 REQ |
|
11 CLS |
|
17 DSP |
|
23 ACC |
|
29 IPS |
|
6 EXH |
|
12 OBG |
|
18 PRE |
|
24 INC |
|
30 PMS |
|
Table 43: Primary Valence Characters
(when accompanied by alternate form of underposed Version diacritic)
1 MNO |
|
4 RCP |
|
7 DUP |
|
10 IMT |
|
13 IDC |
|
2 PRL |
|
5 CPL |
|
8 DEM |
|
11 CNG |
|
14 MUT |
|
3 CRO |
|
6 NNR |
|
9 RES |
|
12 PTI |
|
|
|
Table 44: Primary Validation Characters
(when accompanied by alternate form of underposed Version diacritic)
|
1 CNF |
|
4 INF |
|
7 PSM2 |
|
10 CJT |
|
13 PUT |
|
2 AFM |
|
5 ITU |
|
8 PPT |
|
11 DUB |
|
14 IPB |
|
3 RPT |
|
6 PSM |
|
9 PPT2 |
|
12 TEN |
|
|
|
11.3.2 Secondary Case/Aspect Characters
The neutral, default shape for a secondary case/aspect character is as follows: 
The common recognizable element in all secondary case/aspect characters, and what distinguish them from other character types is a diagonal bar extending from the top-line of the character (or even beyond the top-line) all the way to the bottom-line of the character (or even below the bottom-line of the character). This diagonal line can be interrupted at the mid-line by a horizonatally offset juncture or be broken into two separate diagonal lines, but the continuation of the diagonal past the mid-line will always be in the same direction as on the other side of the mid-line. Examples were shown in Section 11.1.2 above.
A secondary case/aspect character normally conveys all of the following categories of information: Case, Aspect, Modality, Phase and Sanction. It can also indicate the categories of Designation and Perspective using the same laterally-placed diacritic as described in Section 11.3.1.4 above. The diagonal bar portion of the character which indicates case normally runs from the upper-right corner of the character to the lower-left corner. The upper-left portion of the character “above” the diagonal bar indicates Aspect, while the lower-right portion “below” the diagonal bar indicates Modality. Phase is indicated by a superposed diacritic above the character, while Sanction is indicated by an underposed diacritic below the character.
If the diagonal bar indicating case has its orientation reversed (i.e., made to run from upper-left to lower-right) then the section “below” the diagonal normally reserved for indicating Modality, will instead indicate a second aspect.
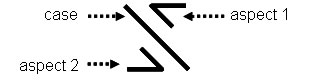
11.3.2.1 Case: The secondary case/aspect character indicates case via the diagonal bar portion of the character, as per the following table. The dotted horizontal lines represent the top-line, mid-line, and bottom-line of the line of writing, in order to illustrate which characters extend above the top-line or dip below the bottom-line.
Table 45: Secondary Case Characters (Note that for the purposes of this table, the VOCATIVE case is shown in Position No. 48.)
1 OBL |
|
25 PUR |
|
49 EXC |
|
73 CMP1A |
|
2 IND |
|
26 CSD |
|
50 AVR |
|
74 CMP1B |
|
3 ABS |
|
27 ESS |
|
51 CMP |
|
75 CMP1C |
|
4 ERG |
|
28 ASI |
|
52 SML |
|
76 CMP1D |
|
5 EFF |
|
29 FUN |
|
53 ASS |
|
77 CMP1E |
|
6 AFF |
|
30 TFM |
|
54 CNR |
|
78 CMP1F |
|
7 DAT |
|
31 REF |
|
55 ACS |
|
79 CMP1G |
|
8 INS |
|
32 CLA |
|
56 DFF |
|
80 CMP1H |
|
9 ACT |
|
33 CNV |
|
57 PER |
|
81 CMP2A |
|
10 DER |
|
34 IDP |
|
58 PRO |
|
82 CMP2B |
|
11 SIT |
|
35 BEN |
|
59 PCV |
|
83 CMP2C |
|
12 POS |
|
36 TSP |
|
60 PCR |
|
84 CMP2D |
|
13 PRP |
|
37 CMM |
|
61 ELP |
|
85 CMP2E |
|
14 GEN |
|
38 COM |
|
62 ALP |
|
86 CMP2F |
|
15 ATT |
|
39 CNJ |
|
63 INP |
|
87 CMP2G |
|
16 PDC |
|
40 UTL |
|
64 EPS |
|
88 CMP2H |
|
17 ITP |
|
41 ABE |
|
65 PRL |
|
89 CMP3A |
|
18 OGN |
|
42 CVS |
|
66 LIM |
|
90 CMP3B |
|
19 PAR |
|
43 COR |
|
67 LOC |
|
91 CMP3C |
|
20 CRS |
|
44 DEP |
|
68 ORI |
|
92 CMP3D |
|
21 CPS |
|
45 PVS |
|
69 PSV |
|
93 CMP3E |
|
22 PRD |
|
46 PTL |
|
70 ALL |
|
94 CMP3F |
|
23 MED |
|
47 CON |
|
71 ABL |
|
95 CMP3G |
|
24 APL |
|
48 VOC |
|
72 NAV |
|
96 CMP3H |
|
11.3.2.2 Aspect: Aspect in a secondary case/aspect character is shown via the portion of the character “above” the diagonal bar. The forms below are the default forms when used in the upper-left portion of the character. For laterally reversed characters, these should be, in turn, laterally reversed, and placed in the upper-right portion of the character. When used to show a second aspect in laterally reversed characters, the form should be vertically inverted and placed in the lower-left portion of the character.
Table 46: Secondary Aspect Characters - shown with OBLIQUE case marking
1 RTR |
|
9 RSM |
|
17 PMP |
|
25 DSC |
|
2 PRS |
|
10 CSS |
|
18 CLM |
|
26 CCL |
|
3 HAB |
|
11 RCS |
|
19 PTC |
|
27 CUL |
|
4 PRG |
|
12 PAU |
|
20 TMP |
|
28 IMD |
|
5 IMM |
|
13 RGR |
|
21 MTV |
|
29 TRD |
|
6 PCS |
|
14 PCL |
|
22 CSQ |
|
30 TNS |
|
7 REG |
|
15 CNT |
|
23 SQN |
|
31 ITC |
|
8 EXP |
|
16 ICS |
|
24 EPD |
|
32 CSM |
|
11.3.2.3 Modality: The thirty modalities are indicated in the portion of a secondary case/aspect character “below” the diagonal bar. The particular forms are the same as the first thirty aspect forms, only vertically inverted and laterally reversed, as shown in the following table.
Table 47: Secondary Modality Characters - shown with OBLIQUE case marking
1 DES |
|
7 OPR |
|
13 IMS |
|
19 NEC |
|
25 CML |
|
2 ASP |
|
8 CPC |
|
14 ADV |
|
20 DEC |
|
26 DVR |
|
3 EXV |
|
9 PRM |
|
15 ITV |
|
21 PTV |
|
27 DVT |
|
4 CRD |
|
10 PTN |
|
16 ANT |
|
22 VOL |
|
28 PFT |
|
5 REQ |
|
11 CLS |
|
17 DSP |
|
23 ACC |
|
29 IPS |
|
6 EXH |
|
12 OBG |
|
18 PRE |
|
24 INC |
|
30 PMS |
|
11.3.2.4 Phase: The nine phases (see Section 5.5) are shown via a diacritic mark placed over the secondary case/aspect character, as per the following:
Table 48: Phase Diacritics Placed Over Secondary Case/Aspect Characters
1 CTX |
2 PCT |
3 ITR |
4 REP |
5 ITM |
6 RCT |
7 FRE |
8 FRG |
9 FLC |
|
|
|
|
|
|
|
|
|
11.3.2.5 Sanction: The nine sanctions (see Section 5.6) are shown via a diacritic mark placed below the secondary case/aspect character, as per the following:
Table 49: Sanction Diacritics Placed Under Secondary Case/Aspect Characters
1 PPS |
2 EPI |
3 ALG |
4 IPU |
5 RFU |
6 REB |
7 THR |
8 EXV |
9 AXM |
|
|
|
|
|
|
|
|
|
11.3.2.6 Placeholder Character for Phase/Sanction: If there is no secondary Case/Aspect character (or Tertiary character as described below) available by which to display the Phase and/or Sanction diacritics, then a special placeholder character is used, consisting of a single vertical bar extending from the top-line to the bottom-line.
11.3.3 Tertiary Characters
The third type of character is the tertiary character. The common recognizable element in all tertiary characters, and what distinguishes them from other character types is a horizontal bar extending across the mid-line of the character, not connected to those portions of the character above or below the mid-line. The two ends of this horizontal bar may be modified. Examples were shown in Section 11.1.3 above.
A tertiary character normally conveys one of the following sets of grammtical information: Aspect 1 + Aspect 2, Aspect + Modality, Valence + Aspect, Validation + Aspect, Validation + Modality, Valence + Modality, or Valence + Validation. The particular set of information being conveyed is indicated by the “ends” of the horizontal mid-line bar of the character, as follows:

The forms utilized above and/or below the horizontal bar for showing aspect and modality are the same as those used for for secondary case/aspect characters (shown in Sections 11.3.2.2 and 11.3.2.3 above), vertically inverted and laterally reversed when used below the horizontal mid-line bar. Likewise, valence and validation are each shown by the first fourteen forms used for showing Aspect from Section Section 11.3.2.2 above, again vertically inverted and laterally reversed when used below the horizontal mid-line bar.
As with secondary case/aspect characters, the categories of Phase and Sanction can be displayed on a tertiary character via superposed and underposed diacritics respectively as per Tables 48 and 49 above. The categories of Designation and Perspective can likewise be shown on a tertiary character utilizing the same mid-line diacritics described previously in Section 11.3.1.4.
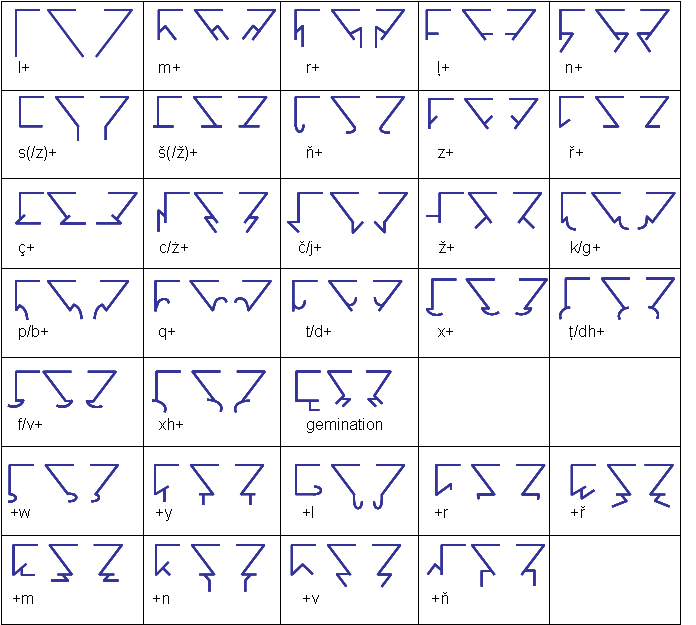
11.3.4 Consonantal Characters
Consonantal characters, the fourth type of character, are discernible by a horizontal bar along the top-line of the character, or when vertically inverted, along the bottom-line of the character. This horizontal bar will always be connected to the remaining portion of the character. The “ends” of the top-bar as well as the ends of the other bars making up the character are subject to numerous modifications and extensions. Examples of consonantal characters were shown in Section 11.1.4 above.
Consonantal characters will always be the last group of characters in a word, following any and all Type 1, 2, or 3 characters. They convey the following information: main root plus its Pattern, Stem and Relation; incorporated root (if present) plus its Pattern, Stem and Designation; Function; Format; Context; Illocution; Suffixes; and Bias. The manner in which these pieces of morphology are conveyed is described in the sub-sections below.
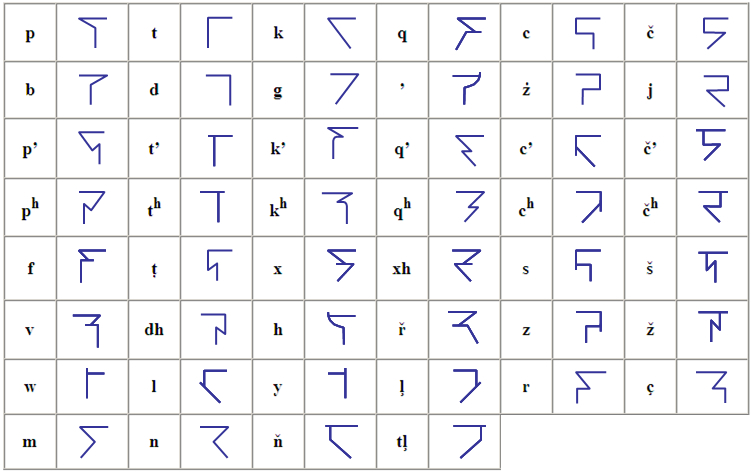
11.3.4.1 Main Root: If there is no incorporated root in the formative, then the first consonantal character in the word will be the main root consonant form, represented by a single consonant character. This character conveys the actual root Cr form (see Section 2.1), whether the root is one up to five consonants in length. The consonant forms are shown in the table below.
Table 50: Basic Consonantal Characters
p |
t |
k |
q |
c |
č |
||||||
b |
d |
g |
’ |
ż |
j |
||||||
p’ |
t’ |
k’ |
q’ |
c’ |
č’ |
||||||
ph |
th |
kh |
qh |
ch |
čh |
||||||
f |
ţ |
x |
xh |
s |
š |
||||||
v |
dh |
h |
ř |
z |
ž |
||||||
w |
l |
y |
ļ |
r |
ç |
||||||
m |
n |
ň |
tļ |
Various extensions added to the above forms allow for the prefixing of various consonants, e.g., t --> lt. These extensions which prefix consonants to existing consonant forms are shown below:
Table 51: Consonantal Character Extensions Indicating Consonant Prefixes
l+C |
m+C |
r+C |
ļ+C |
n+C |
|||||
s+C (z+C) |
š+C (ž+C) |
ň+C | z+C | ř+C | |||||
ç+C |
c+C |
č+C / |
ž+C |
k+C / |
|||||
p+C |
q+C |
t+C |
x+C |
ţ+C / |
|||||
f+C |
xh+C |
gemination |
|||||||
Additional extensions allow for the suffixing of various consonants, e.g., t —> tl, as shown below:
Table 52: Consonantal Character Extensions Indicating Consonant Suffixes
| C+w | C+y | C+l | C+r | C+ř | |||||
| C+m | C+n | C+v | C+ň |
Various diacritics are also available for placement underneath the Cr character, used in conjunction with the above sets of extensions in order to indicate tri-consonantal stems and tetra-consonantal stems.
Table 53: Underposed Diacritics to Consonant Characters Indicating Consonant Affixes
C+w
|
C+y
|
C+l
|
C+r
|
C+ř
|
C+m
|
C+n
|
s+C
|
z+C
|
š+C
|
ž+C
|
f/v+C
|
ţ/dh+C
|
|
If a tri-consonantal or tetra-consonantal stem cannot be unambiguously indicated using the above extensions and diacritics on a consonantal character, then the Cr root can be written using two characters, the second one being a placeholder character consisting of a vertical bar without a horizontal top-bar, running from the top-line to the bottom-line, to which the various extensions shown in Tables 51 and 52 are added.
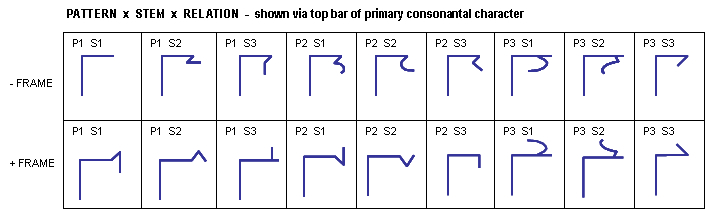
11.3.4.2 Pattern, Stem and Relation: These categories (see Sections 2.2 and 5.4) are shown via extensions or modifications made to the horizontal top-bar (or bottom-bar if the character is inverted) of the Cr consonantal character, as follows:
Tables 54a and 54b:
Consonantal Character Extensions Indicating Pattern, Stem, and RelationUNFRAMED Relation
|
P1 S1 |
P1 S2 |
P1 S3 |
P2 S1 |
P2 S2 |
P2 S3 |
P3 S1 |
P3 S2 |
P3 S3 |
FRAMED Relation
|
P1 S1 |
P1 S2 |
P1 S3 |
P2 S1 |
P2 S2 |
P2 S3 |
P3 S1 |
P3 S2 |
P3 S3 |
11.3.4.3 Function: The category of Function (see Section 5.1) is shown by a superposed diacritic above the Cr consonantal character:
Table 55: Superposed Diacritics to Cr Character Indicating Function
STA |
DYN |
MNF |
DSC |
|
|
|
|
11.3.4.4 Incorporated Root plus Pattern, Stem, and Designation: Incorporated roots are shown using the same consonantal characters as for the Cr main root in Section 11.3.4.1 above. The character representing the incorporated root is place immediately preceding the Cr main root character (i.e., so that it becomes the first Type 4 character in the word), and it is vertically inverted. Its pattern and stem are shown using the same extensions/modifications to its horizontal bar (now on the bottom-line rather than the top due to vertical inversion of the character), as shown above for the Cr character. Formal designation of the incorporated root is shown by using the FRAMED alternatives of the Pattern+Stem extensions/modifications.
11.3.4.5 Format: Any formative containing an incorporated root must show the category of Format (see Section 6.4). This is shown by a combination of diacritics above both the incorporated root character and the Cr main root character, as well as vertical inversion of the Cr character. Since the Cr main root character may already carry diacritics indicating the formative’s function, such diacritics will be subject to modification. The values in the table below show an inverted ‘t’ consonantal character representing the incorporated root, followed by a standard ‘t’ consonantal character representing the main root. The pattern of diacritics is shown on these two characters:
Table 56: Pattern of Diacritics and Inversion of Cr Character to Indicate Format
11.3.4.6 Context: The default EXS Context (see Section 3.6) is unmarked. The three other contexts are shown via a superposed diacritic over the Cr character (or underposed below the character if it is inverted). If the Cr character already has a diacritic showing Function or Function+Format, it is modified as per the table below:
Table 57: Modification of Function(+Format) Diacritics on Cr Character to Indicate Context
EXS |
FNC |
RPS |
AMG |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
11.3.4.7 Illocution: This category (see Section 5.3) is shown via a diacritic mark alongside the Cr character at the mid-line following the character in the direction the particular line of writing is written (unless the diacritic can be written “inside” a character whose shape has an obvious interior space, e.g., the l and x consonantal characters).
Table 58: Illocution Diacritics on Cr Character
ASR |
IRG |
DIR |
ADM |
HOR |
DEC |
|
|
|
|
|
|
11.3.4.8 Negative Polarity: The Ithkuil script allows for a “shortcut” representation of the NA11/5 negation suffix, the most common method of negating a verb in Ithkuil. This shortcut is accomplished via a diacritic mark alongside the Cr character at the mid-line following the character in the direction of writing. The character is shown below in the first box of Table 59. Since this diacritic position is the same utilized for showing Illocution (see Table 58 above), the Illocution diacritics are modified to indicate this negation, as follows:
Table 59: Illocution Diacritics on Cr Character Modified to Show Negative Polarity
ASR |
IRG |
DIR |
ADM |
HOR |
DEC |
|
|
|
|
|
|
11.3.4.9 Suffixes: Derivational (Slot XI) Suffixes (see Chapter 7) are shown by additional Type 4 consonantal characters, placed following the Cr consonantal character. Each such character represents one VxC suffix, its formation of prefixed and suffixed consonants identical to the character formation principles previously described for the Cr consonantal character, utilizing the same extensions and modifications shown in Tables 51 and 52 above.
Suffix-Type: The default consonantal character is used to represent Type-1 suffixes. Types 2 and 3 are shown in the following ways: Type-2 suffixes are shown by vertically inverting the consonantal character. Type-3 suffixes are shown by an underposed dot diacritic beneath the consonantal character.
Suffix Degree: The nine suffix degrees are shown via superposed diacritics above the consonantal character (even if the character is vertically inverted to represent a Type-2 suffix). The diacritics are shown in the following table.
Table 60: Diacritics Representing Suffix Degree
Degree 1 |
Degree 2 |
Degree 3 |
Degree 4 |
Degree 5 |
Degree 6 |
Degree 7 |
Degree 8 |
Degree 9 |
|
|
|
|
(none) |
|
|
|
|
11.3.4.10 Bias: The category of Bias (see Section 5.11) is shown by modification of the top-bar of a consonantal suffix character. If the formative does not carry a VxC suffix, then the modification is made to a special placeholder character consisting of a top-bar alone with no stem.
The modifications are mostly the same modifications made to Cr characters for showing Pattern, Stem, and Relation, as shown previously in Tables 54a and 54b, supplemented by additional underposed diacritics placed beneath the bottom-line of the character (shown next to the character in the following table). Note that for the last 16 biases whose representation utilizes a vertical-bar diacritic, if the placeholder top-bar character is used to represent these biases, then the character is laterally reversed rather than utilizing the vertical-bar diacritic.
Table 61: Modifications to Consonantal Suffix Characters to Show Bias
ASU |
HPB |
COI |
ACP |
RAC |
STU |
CTV |
DPV |
|
| Intensive Forms | ASU+ |
HPB+ |
COI+ |
ACP+ |
RAC+ |
STU+ |
CTV+ |
DPV+ |
RVL |
GRT |
SOL |
SEL |
IRO |
EXA |
LTL |
CRR |
|
| Intensive Forms | RVL+ |
GRA+ |
SOL+ |
SEL+ |
IRO+ |
EXA+ |
LTL+ |
CRR+ |
EUP |
SKP |
CYN |
CTP |
DSM |
IDG |
SGS |
PPV |
|
| Intensive Forms | EUP+ |
SKP+ |
CYN+ |
CTP+ |
DSM+ |
IDG+ |
SGS+ |
PPV+ |
| 11.4 WORD BOUNDARIES, PUNCTUATION, AND ALPHABETIC TRANSLITERATION |
Because all written words begin with characters other than Type 4 (consonantal characters), while all words end with Type 4 characters, it is always possible to determine where new words begin in a line of Ithkuil writing, obviating the need for a blank space or other boundary between words. In turn, a blank space functions to indicate a sentence boundary. And because Ithkuil morphology already indicates within words themselves various attitudes, moods, and other information which are normally indicated supra-segmentally in Western languages (e.g., by tone or inflection of the voice, hyper-enunciation, etc.), symbols corresponding to exclamation points and question marks are likewise unnecessary. The Ithkuil equivalents to subordinate and relative clauses are likewise indicated morphologically, as are coordinative/serial lists of words, therefore there is no need for any equivalent to the comma.
The only “punctuation” symbols used are to show quotations of direct speech and phonetic transliteration (as when spelling non-Ithkuil words and names). These two sets of symbols are shown below. Note that the quotation marks are used only to indicate direct speech; they are not used as in English to offset a word for emphasis or special usage. The phonetic rendering marks indicate the word or phrase between the marks is to be pronounced phonetically (i.e., alphabetically).
insert quote here
insert transliteration here
11.4.1 Alphabetic Transliteration
Proper names and other non-Ithkuil words, when transliterated into Ithkuil, are written alphabetically between the phonetic transliteration marks shown above. Consonants are written using the Type 4 consonant characters, utilizing the extensions from Tables 51 and 52 above (but not the diacritics from Table 53) to represent various consonant clusters or gemination. Transliteration is based on either a phonemic or phonetic representation of the non-Ithkuil word, without concern for any spelling conventions contained in the original/native script of the foreign word or name. Vowels are represented in the following ways:
Vowels: For vowels preceding or following a consonant (or consonant conjunct) the top-bar modifications normally used for representing Pattern, Stem, and Relation are used – the vowel thereby being represented as part of the consonant character. If there is no consonant in the syllable to carry the vowel, a placeholder symbol consisting of a top-bar alone is used. These top-bar modifications are shown in the following tables (note that the vowel-sounds are indicated using the International Phonetic Alphabet):
Table 62: Modifications to Consonant Characters to Transliterate Accompanying Vowel
modification: |
|||||||||
IPA value: |
(none) |
a |
æ |
ɑ |
o |
ε |
e |
I |
modification: |
|||||||||
IPA value: |
i |
ə |
u |
y |
œ |
ø |
By default, the vowel is to be pronounced following the consonantal form. If instead the vowel is to be pronounced preceding the consonant, the character carries a superposed dot diacritic. If there are two vowels in a row and there is no consonant character to carry the vowel, a placeholder consonant character is used consisting of a lone top-bar. Syllabic stress is shown by a superposed horizontal bar diacritic; if a dot diacritic is already present above the character, it changes to a vertical bar diacritic for stressed syllables. Diphthongs and long vowels are indicated by diacritics placed alongside the character in the direction of writing (unless the diacritic can be written “inside” a character whose shape has an obvious interior space, e.g., the l and x consonantal characters). Diphthongs ending in an -i/-y semivowel are indicated with a dot, those ending in -u/-w by a small vertical bar, and long vowels by a small horizontal bar.
Tone: If necessary to transliterate a word carrying tone, the following underposed diacritics may be used under the consonant+vowel character corresponding to the syllable containing the toneme.
Table 63: Diacritics to Consonant Characters for Transliteration of Syllabic Tone
low
high
mid
rising
falling
fall-rise
rise-fall
Note on Placenames and Ethnonymns: In general, the Ithkuil names of real-world placenames and ethnonymns are the same as the native form to the extent that Ithkuil phonology allows and to the extent that such native terms can be distinguished. Otherwise, alternate names in common usage can be utilized. So, for example, the most technically correct Ithkuil name for China would be îpal –Čuňˇkwo, based on Ithkuil’s closest available phonological equivalent to the Mandarin Zhōngguó (IPA [![]() ]), although the name îpal Čin, based on the historically derived root (from both Persian and Sanskrit) would be acceptable as well.
]), although the name îpal Čin, based on the historically derived root (from both Persian and Sanskrit) would be acceptable as well.
For placenames with multiple native names from equally official languages (e.g., the four names of Switzerland in each of its four official languages), the Ithkuil phonological equivalent to any official name is acceptable. For names whose native ethnonymn is not common knowledge or not readily discoverable (e.g., the Andi people of Dagestan whose native ethnonymn is variously given as Qwannal, Qwannab, Khivannal), a name in common use can be used even if it is derived from a non-native source (e.g., the Russian-derived name “Andi”).
The author intends at some future point to add a section to the Lexicon on the official Ithkuil names of major non-Ithkuil placenames and ethnonymns.
Language Names: The Ithkuil name of a non-Ithkuil language is given by the native ethnonymn of the people or their nation/placename with the addition of the SSD1/5 suffix -(a)k added to the carrier root preceding the alphabetic name.
| 11.5 HANDWRITTEN FORMS OF THE CHARACTERS |
The various charts below display the handwritten equivalents to the various character types, the extensions to top bars and bottom bars, diacritics, etc.
Primary Characters

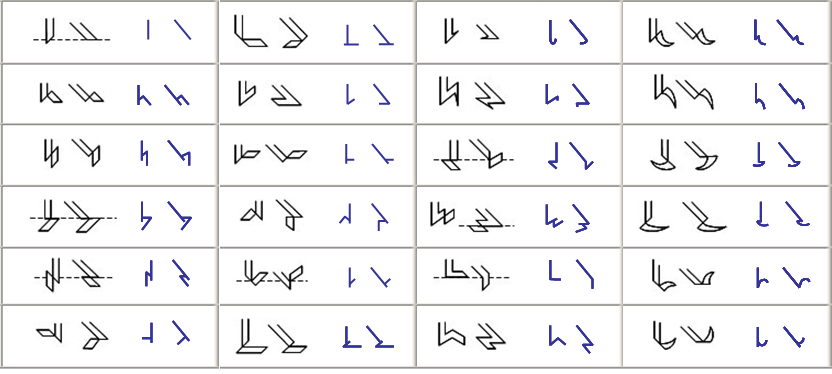
![]()
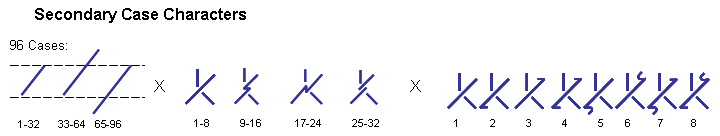
Secondary Aspect Characters

Tertiary Characters
Consonantal Characters
Consonantal Extensions (Shown on -t-, -k-, and -g- characters)
| 11.6 THE ALTERNATIVE ORNAMENTAL SCRIPT |
The now defunct previous revision of Ithkuil known as Ilaksh utilized an experimental two-dimensional, non-linear writing system of colorful “cartouche”-like containers and hexagonal glyphs used to fashion an abstract morphological “map” of an Ilaksh sentence. Now that the Ilaksh language has been withdrawn, it is the author’s intention to eventually adapt this writing system to Ithkuil, for use as an alternative, “ornamental” writing system for artistic purposes. When this adaptation is ready it will be placed in this section of the grammar. The graphic below illustrates a draft sample of what this writing system will look like.

Proceed to Chapter 12: The Number System>>